


Cal.com v4.9.3
Cal.com v4.9.3
Existing customer? Login
Get StartedFor some time, the Cal.com app could suffer from long cold start load times ranging from 7 seconds to 30 seconds, in extreme cases. This behaviour did not always happen due to the nature of cold starts but it was happening frequently enough to where it became an issue we needed to address as soon as possible.
For those not familiar with cold starts, there are plenty of materials out there describing the problem in general so we won’t be covering that. What we hope to do with this blog is explain the exact root cause that was affecting our system in particular, which was induced by cold starts in a serverless environment.
To start, let’s look at the following log from Vercel:
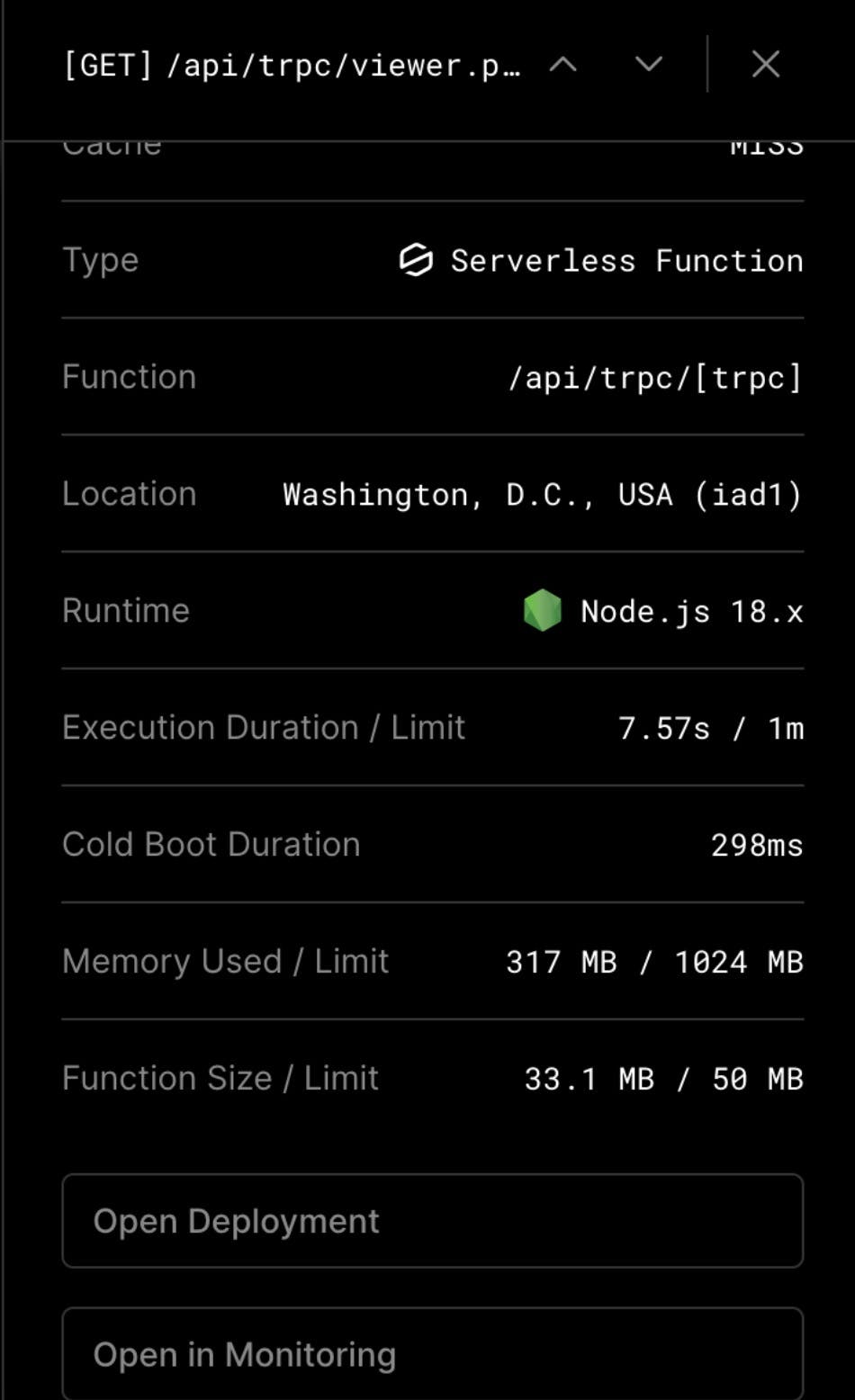
For the /api/trpc/[trpc] function, we see a Cold Boot Duration of 298ms but an Execution Duration of 7.57s. This is a bit odd, right? The cold boot itself is not the problem but instead, it’s what’s loading upon the cold boot that’s causing the Execution Duration to inflate badly.
So where do we start to find the root cause of this?
After seeing the Function Size of 33.1 MB, our team, the community and the Vercel and Prisma folks directly dove in and started bundle analyses and compilation logging to try and find which packages were weighing down our functions. Even though this Function Size is under the limit of 50MB, we believed it could still be at least partly the culprit.
We did identify a few large dependencies being loaded as part of our session retrieval which was able to be slimmed down (PR) and we lazy loaded our app store dependencies (PR).
Performance did improve on each request following these updates but it was not the multiple-second reduction we were hoping for. So what else could it be? Is Prisma slow to connect upon cold start in our serverless setup?
We already had Prisma Data Proxy running in production to handle our connection pooling so we were sceptical it was the issue but nonetheless, we wanted to do our due diligence to ensure ourselves of that.
In an experimental branch, we spun up a test endpoint segregated from our API routes and pages in a separate app route (using the new App Router from Next.js) that only got the count of users in the system. The performance of this route on cold starts could run up to 1 second, which showed us that Prisma can have a slight delay on cold starts, but again, it was not the 7-15 seconds we were seeing on average.
From the bundle analysis that had been done, it was clear that our app loads a lot of dependencies. That triggered the idea to reduce what was loaded on every API request. Knowing API routes in Next.js load the _app.tsx file, we decided to implement a PageWrapper that contains all of the dependencies needed for non-API routes (PR).
Again, this is a nice improvement in terms of dependency optimization but we still had our long wait times.
After shipping loads of perf-specific PRs that helped with code organization, speed and bundle size, we still had not found the golden bullet. It was time to come full circle and think in terms of bottlenecks since many performance issues are related to bottlenecks, right?
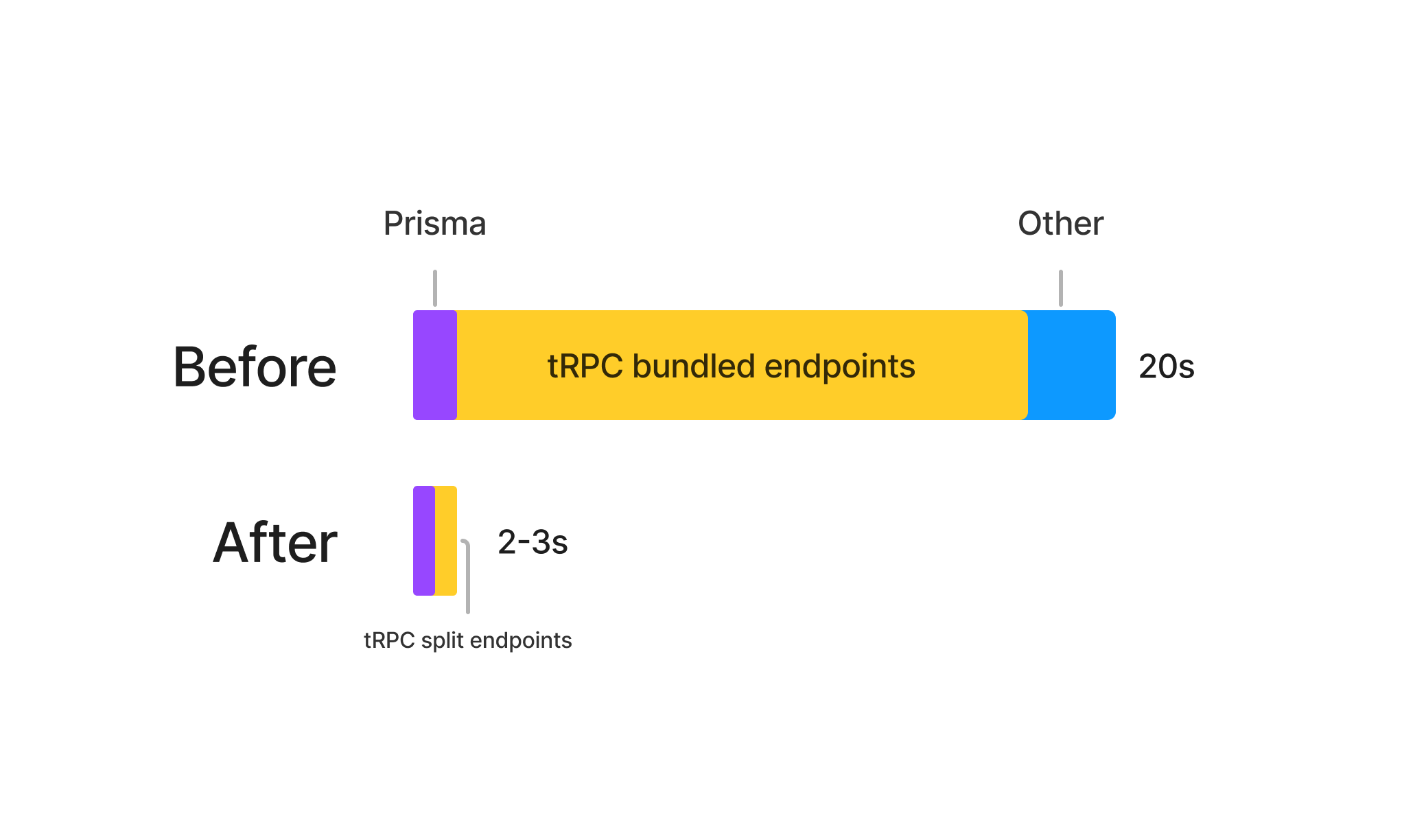
Using this train of thought, a test was run to split the simplest tRPC router into its own API route. For us, that was our public router. After deployment, the /api/trpc/viewer.public.i18n endpoint was now /api/trpc/public/i18n. We saw a decrease from 15 seconds down to 2 seconds in cold start times for this route. This seemed to tease out the fact that our single tRPC router was indeed the bottleneck.
Simply put, we had too many tRPC routers going into the main viewer router exposed on the /api/trpc/[trpc] route. This meant that the very first call to this function, whether it be to load i18n terms or to get a user’s schedule, needed to import all 20 routers and all of their dependencies.
Seen here in what was ultimately the PR that resolved most of our long cold start problems, there was a suspicion that the slots router was too big and was the root of the issues. Unfortunately, after splitting the slots router into its own Next.js API route, we were still seeing large bundle sizes and long cold start times. For these reasons, this PR was left untouched while other hypotheses were pursued.
After the discovery of the i18n route loading in 2 seconds on cold starts, the aforementioned PR was then built upon so that all tRPC routers had their own API route. When split, Vercel creates separate functions per route.
So why does splitting the tRPC routers into their own Next.js API routes fix the issue? The simple answer, for our case, is that even if a page calls 5 different tRPC routes to load data, they will run concurrently and thus the effect of loading dependencies for all routers is not compounded. We can now still see cold start times of 2-3 seconds on any given tRPC route but since they are called concurrently by the browser, the total wait time can be 3 seconds, not 7-15 seconds (or 30 seconds in the extreme cases).
We recognize there is still more work to be done to reduce these speeds even further but the reductions thus far have been significant.
Here's an issue to promote potential changes for tRPC in serverless environments.

A major shoutout and thank you to everyone who contributed to resolving this issue. From writing custom scripts that helped determine which dependencies were bogging our system down to opening PRs, we really appreciate the support and effort put into resolving these issues. We hope this blog and the PRs can provide a bit of insight into the experiments we ran and the root cause we eventually found.
Special thanks to Julius Marminge from tRPC.io, Guillermo Rauch, Malte Ubl and Jimmy Lai from Vercel and Lucas Smith. 🙏
While this has been a huge achievement we're still working hard to both reduce cold starts even more but also improve the self-hosting experience without a serverless architecture. Stay tuned!
Cal.com v4.9.3
Checkout product updates, performance improvements, new features, and code changes in Cal.com v4.9.4







